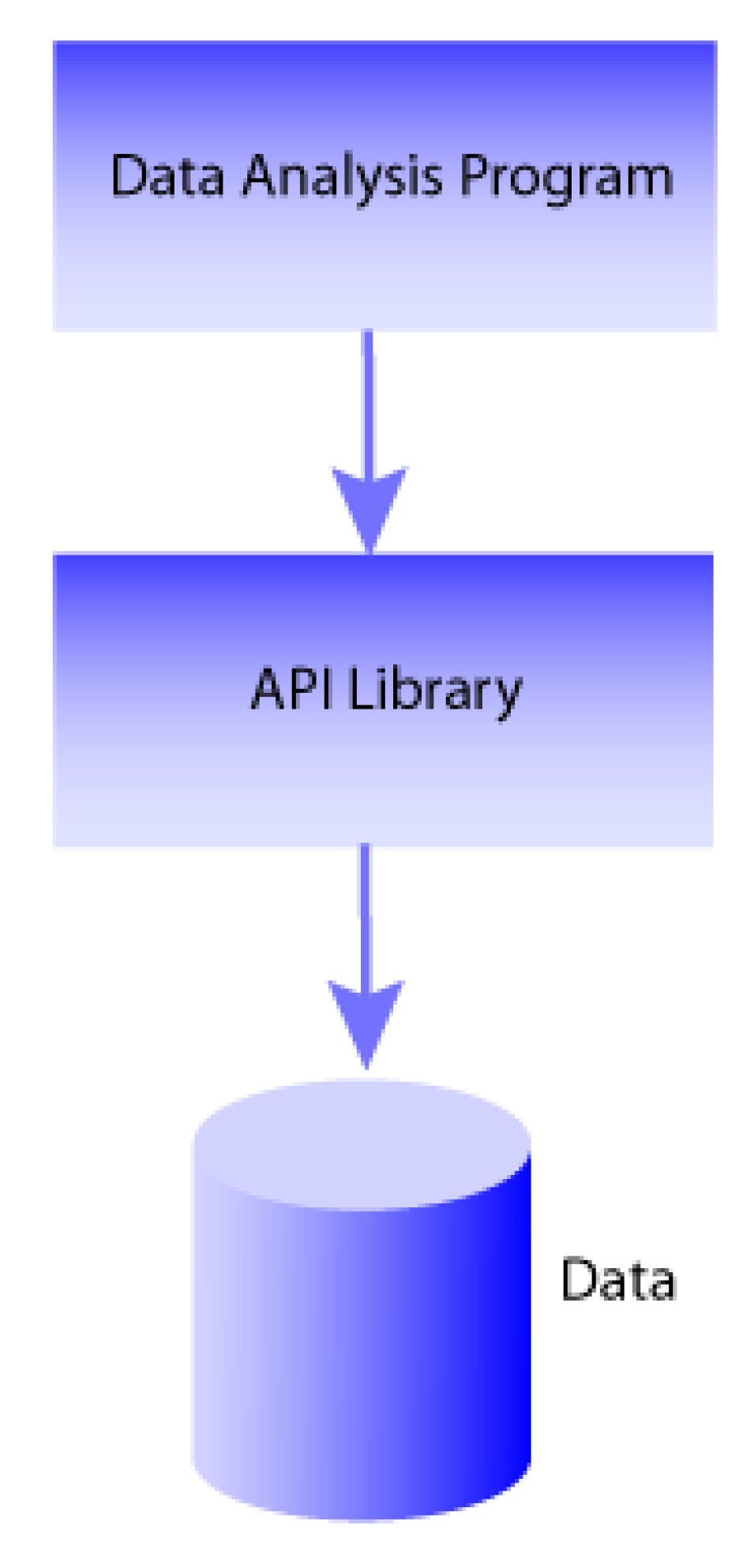
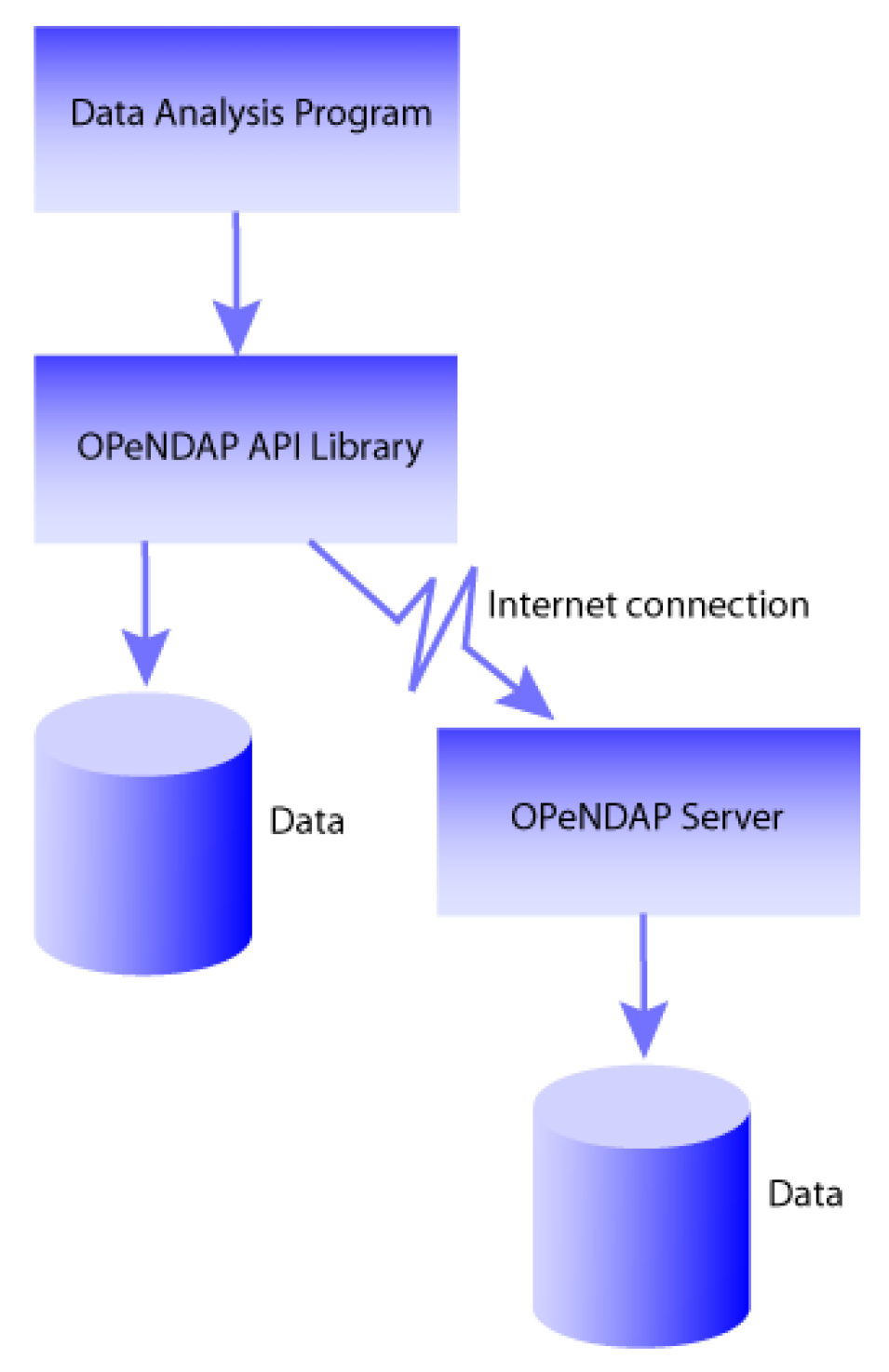
OPeNDAP also provides data translation functionality. Data from the original data file is translated by the OPeNDAP server into the OPeNDAP data model for transmission to the client. Upon receiving the data, the client translates the data into the Data Model it understands. Because the data transmitted from an OPeNDAP server to the client travel in the OPeNDAP format, the dataset’s original storage format is completely irrelevant to the client. For example, if the client was originally designed to read NetCDF format files, the data returned by the OPeNDAP-enabled NetCDF library will appear to have been read from a NetCDF file. Similarly, if the program uses C, Python, Java or JavaScript there are OPeNDAP API libraries that will enable it to directly access data. Finally, if a program can read data from files using any of the server’s supported format, it is easy to use the OPeNDAP server to send you data in a file and use that just like any other local data file.
OPeNDAP does not claim to remove all of the overhead of data searches. A user will still have to keep track of the URLs of interesting data in the same way a user must now keep track of the names of files. (You may run across datasets where the data consists of OPeNDAP URLs. These are the OPeNDAP file servers and have been developed by OPeNDAP users to organize datasets consisting of large numbers of individual files.) But OPeNDAP does make the access to that data simpler and quicker.
The OPeNDAP group provides a whole array of client software to implement this communication standard. These range from standalone clients to libraries to link with existing software. In addition, a community of like-minded software developers and data users has built compatible software that extends the software we offer in many new directions.
2.2. OPeNDAP Services
The communication between an OPeNDAP client and server is specified by the DAP. This defines the range of messages a server must understand and the kinds of replies it makes.
There are two categories of messages that an OPeNDAP server can understand. Some are required by the DAP and others are merely suggested. A server is considered to be DAP-compliant if it can respond intelligibly to the required messages. Following are the requests messages a server is required to understand:
Data Description
Data values come in types and sizes. An array, for example, might consist of 10 integers. The value "ten" and the type "integer" describe the array. This request returns information about data types, so that a receiving program can allocate space appropriately. See Data Description Structure (DDS) in this guide.
Data Attribute
This is a request to provide information about data and typically includes information like units, names of data types, reference information and so on. See Data Attribute Structure (DAS) in this guide.
Data
The server also must be able to respond to a request for the data itself. See DDS in this guide.
In addition, a server may respond to requests like these:
ASCII
Some servers can convert data to ASCII values on the fly. This allows users to view data using a standard web browser, assuming the data are not too large. See ASCII Service in this guide.
Info
The info response is a formatted page containing information from the Data Attributes and Data Description responses. It is meant to be a human-readable means to show what is available in a dataset via a standard web browser. See Info Service in this guide.
HTML
Very similar to the info response, the HTML response provides the information from the info response and also includes a JavaScript form to help you build a request for data from the same data file. The best description of the HTML form is in the main OPeNDAP page.
SOAP
While existing SOAP queries may continue to work, SOAP is has been deprecated and is not actively suppored by OPeNDAP servers.
DDX
The Document Description XML (DDX) file is an XML version of the Data Attribute and Data Description replies. See DDX in this guide.
2.3. The OPeNDAP Server (aka "Hyrax")
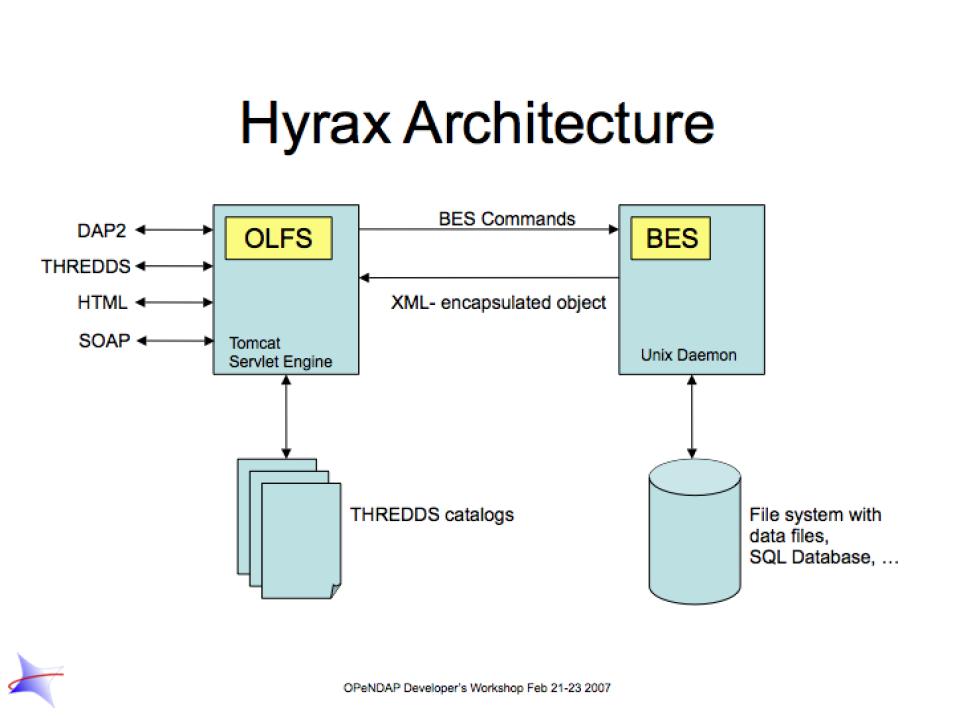
OPeNDAP provides a definition of the communication between client and server and enables servers and clients that conform to DAP standard to communicate with each other. In addition to the DAP communication standard itself, the OPeNDAP group also provides an implementation of a standard server protocol, called _Hyrax.
For most data consumers, the architecture of Hyrax is not important since they see only its web interface (through a browser or by pasting URLs into an application). Hyrax is actually made up of two pieces. You can think of them as a front-end and a back-end, though a client will not be aware of the separation. They will often be run on the same machine, and even when they are not, a client will see only the front end.
- The front-end server is a Tomcat servlet and is also called the OPeNDAP Lightweight Front-End Servlet (OLFS). Its job is to receive your request for data and manage all the different forms a request might take. For example, you might be asking for the data, an ASCII version of the data, or a reply to a SOAP message looking for data. The front-end server can also reply to THREDDS catalog requests, for information about the data, and can directly provide some information about the data, too.
- The Back-End Server (BES) is more strictly about performance and is designed to respond quickly and efficiently to requests from the OLFS.
NOTE: Most users will not make requests directly to the BES.
See Data Model in this guide for a description of the data returned by requests and see OPeNDAP Server in this guide for a description of the URL syntax used to send requests.
Go to the OPeNDAP 4 Data Server documentation for a description of how to install and configure an OPeNDAP data server ("Hyrax").
2.4. Administration and Centralization of Data
Under OPeNDAP, there is no central archive of data. Data under OPeNDAP is organized similar to the World Wide Web. To make your data accessable, all that you need to do is to start up a properly configured server on an Internet node that has access to the data to be served. Data providers are free to join and to leave the system as doing so is convenient, just as any proprietor of a web page is free to delete it or add to it as needed.
Similar to the World Wide Web, there are some disadvantages to the lack of central authority. If no one knows about a web site, no one will visit it. Similarly, listing a dataset in a central data catalog, such as the Global Change Master Directory, can make data available to other researchers in a way that simply configuring an OPeNDAP server would not. You can contact the GCMD and submit your server to their catalog.
The remainder of this section will be divided into three sub-sections:
- Instructions on the building and operating of OPeNDAP clients
- A tutorial and reference on running OPeNDAP servers and making data available to OPeNDAP clients
- A technical documentation describing the implementation details (and the motivation behind many of the design decisions) of the OPeNDAP software.
3. OPeNDAP Data Model
This section provides a review of the data types OPeNDAP sends between client and server and issues involved in translating one to another. This information may be useful to researchers who will be using OPeNDAP to transfer data.
3.1. Data and Data Models
Basic to the operation of OPeNDAP is its data model and the set of messages that define the communication between client and server. This section presents the data model (the next section presents the messages).
3.1.1. Data Models
Any data set is made up of data and a data model. The data model defines the type and arrangement of data values and may be thought of as an abstract representation of the relationship between one data value and another. Although it may seem paradoxical, it is precisely this relationship that defines the meaning of a number. Without the context provided by a data model, a number does not represent anything. For example, within some data set, it may be apparent that a number represents the value of temperature at some point in space and time. Without its neighboring temperature measurements, and without the latitude, longitude, height (or depth), and time, the same number is meaningless.
As the model only defines an abstract set of relationships, two data sets containing different data may share the same data model. For example, the data produced by two different measurements with the same instrument will use the same data model, though the values of the data are different. Sometimes two models may be equivalent. For example, an XBT (eXpendable BathyThermograph) measures a time series of temperature near the surface of the ocean, but is usually stored as a series of temperature and depth measurements. The temperature vs. time model of the original data is equivalent to the temperature vs. depth model of the stored data.
In a computational sense, a data model may be considered to be the data type or collection of data types used to represent that data. A temperature measurement might occur as half an entry in a sequence of temperature and depth pairs. However the data model also includes the scalar latitude, longitude, and date that identify the time and place where the temperature measurements were taken. Thus the data set might be represented in a C-like syntax like this:
Example Data Description of XBT Station
Dataset {
Float64 lat;
Float64 lon;
Int32 minutes;
Int32 day;
Int32 year;
Sequence {
Float64 depth;
Float64 temperature;
} cast;
} xbt-station;
The above example describes a data set that contains all the data from a single XBT. The data set is called xbt-station and contains floating-point representations of the latitude and longitude of the station and three integers that specify when the XBT measurements were made. The xbt-station contains a single sequence (called cast) of measurements, which are represented here as values for depth and temperature.
A slightly different data model representing the same data might look like this:
Example Data Description of XBT Station Using Structures
Dataset {
Structure {
Float64 lat;
Float64 lon;
} location;
Structure {
Int32 minutes;
Int32 day;
Int32 year;
} time;
Sequence {
Float64 depth;
Float64 temperature;
} cast;
} xbt-station;
In this example, some of the data have been grouped, implying a relation between them. The nature of the relationship is not defined, but it is clear that lat and lon are both components of location and that each measurement in the cast sequence is made up of depth and temperature values.
In these two examples, meaning was added to the data set only by providing a more refined context for the data values. No other data was added, but the second example can be said to contain more information than the first one.
These two examples are refinements of the same basic arrangement of data. However, there is nothing that says that a completely different data model can not be just as useful or just as accurate. For example, the depth and temperature data, instead of being represented by a sequence of pairs could be represented by a pair of sequences or arrays:
Example Data Description of XBT Station Using Arrays
Dataset {
Structure {
Float64 lat;
Float64 lon;
} location;
Structure {
Int32 minutes;
Int32 day;
Int32 year;
} time;
Float64 depth[500];
Float64 temperature[500];
} xbt-station;
The relationship between the depth and temperature variables is no longer quite as clear, but depending on what sort of processing is intended, the loss may be unimportant.
The choice of a computational data model to contain a data set depends in many cases on the whims and preferences of the user as well as on the data analysis software to be used. Several different data models may be equally useful for a given task and not all data models will contain the same quantity of informaiton.
Note that with a carefully chosen set of data type constructors, such as those we have used in the preceding examples, a user can implement an infinite number of data models. The examples above use the OPeNDAP DDS format, which will become important in later discussions of the details of the OPeNDAP DAP. The precise details of the DDS syntax are described in the DDS section of this guide.
Data Models and APIs
A data access Application Program Interface (API) is a library of functions designed to be used by a computer program to read, write, and sample data. Any given data access API can be said to implicitly define a data model. (Or, at least, it will define restrictions on the data model.) That is, the functions that compose the API accept and return data using a certain collection of computational data types: multi-dimensional arrays might be required for some data, scalars for others, and sequences for others. This collection of data types and their use constitute the data model represented by that API. (Or data models—there is no reason an API cannot accommodate several different models.)
Translating Data Models
The problem of data model translation is central to the implementation of OPeNDAP. With an effective data translator, an OPeNDAP program originally designed to read netCDF data can have some access to data sets that use an incompatible data model, such as an SQL database.
In general, it is not possible to define an algorithm that will translate data from any model to any other model without losing information defined by the position of data values or the relations between them. Some of these incompatibilities are obvious. For example, a data model designed for time series data may not be able to accommodate multi-dimensional arrays. Others are more subtle. For example, a Sequence looks very similar to a collection of Arrays in many respects, but this does not mean they can always be translated from one to the other. For example, some APIs return only one Sequence "instance" at a time. This means that even if a Sequence of sets of three numbers is more or less the same shape as three parallel Arrays, it will be very difficult to model the one kind of behavior on the other kind of API.
However, even though the general problem is not solvable, there are many useful translations that can be done and there are many others that are still useful despite their inherent information loss.
For example, consider a relational structure below, which contains two nested Sequences. The outer sequence represents all the XBT drops in a cruise; the inner sequence represents each XBT drop.
Example Data Description of XBT Cruise
Dataset {
Sequence {
Int32 id;
Float64 latitude;
Float64 longitude;
Sequence {
Float64 depth;
Float64 temperature;
} xbt_drop;
} station;
} cruise;
Note that each entry in the cruise sequence is composed of a tuple of data values (one of which is itself a sequence). Were we to arrange these data values as a table, they might look like this:
id lat lon depth temp
1 10.8 60.8 0 70
10 46
20 34
2 11.2 61.0 0 71
10 45
20 34
3 11.6 61.2 0 69
10 47
20 34
This can be made into an array, although doing so introduces redundancy:
id lat lon depth temp
1 10.8 60.8 0 70
1 10.8 60.8 10 46
1 10.8 60.8 20 34
2 11.2 61.0 0 71
2 11.2 61.0 10 45
2 11.2 61.0 20 34
3 11.6 61.2 0 69
3 11.6 61.2 10 47
3 11.6 61.2 20 34
The data is now in a form that may be read by an API such as netCDF. However, consider the analysis stage. Suppose a user wants to see graphs of each station’s data. It is not obvious simply from the arrangement of the array where one station stops and the next one begins. Analyzing data in this format is not a function likely to be accommodated by a program that uses the netCDF API, even though it is theoretically possible to implement.
3.1.2. Data Access Protocol (DAP)
The OPeNDAP DAP defines how an OPeNDAP client and an OPeNDAP server communicate with one another to pass data from the server to the client. The job of the functions in the OPeNDAP client library is to translate data from the DAP into the form expected by the data access API for which the OPeNDAP library is substituting. The job of an OPeNDAP server is to translate data stored on a disk (in whatever format they happen to be stored in) to the DAP for transmission to the client.
DAP Components
The DAP consists of several components:
- An "intermediate data representation" for data sets. This is used to transport data from the remote source to the client. The data types that make up this representation may be thought of as the OPeNDAP data model.
- A format for the "ancillary data" needed to translate a data set into the intermediate representation and to translate the intermediate representation into the target data model. The ancillary data in turn consists of two pieces:
- A description of the shape and size of the various data types stored in some given data set. This is called the (DDS).
- Capsule descriptions of some of the properties of the data stored in some given data set. This is called the DAS.
- A "procedure" for retrieving data and ancillary data from remote platforms.
- An "API" consisting of OPeNDAP classes and data access calls designed to implement the protocol,
The intermediate data representation and the ancillary data formats are introduced in the OPeNDAP Messages section of this guide, as are the steps of the procedure. The actual details of the software used to implement these formats and procedures is a subject of the documentation of the respective software.
3.1.3. Data Representation
There are many popular data storage formats, and many more than that in use. When these formats are optimized, they are optimized for data storage and are not generally suitable for data transmission. In order to transmit data over the Internet, OPeNDAP must translate the data model used by a particular storage format into the data model used for transmission.
If the data model for transmission is defined to be general enough to encompass the abstractions of several data models for storage, then this intermediate representation—the transmission format—can be used to translate between one data model and another.
The OPeNDAP data model consists of a fairly elementary set of base types combined with an advanced set of constructs and operators that allows it to define data types of arbitrary complexity. This way, the OPeNDAP data access protocol can be used to transmit data from virtually any data storage format.
OPeNDAP Elements
OPeNDAP comprises the following elements:
Base Types
These are the simple data types, like integers, floating point numbers, strings, and character data.
Constructor
Types These are the more complex data types that can be constructed from the simple base types. Examples are structures, sequences, arrays, and grids.
Operators
Access to data can be operationally defined with operators defined on the various data types.
External Data Representation
In order to transmit the data across the Internet, there needs to be a machine-independent definition of what the various data types look like. For example, the client and server need to agree on the most significant digit of a particular byte in the message
These elements are defined in greater detail in the sections that follow.
Base Types
The OPeNDAP data model uses the concepts of variables and operators. Each data set is defined by a set of one or more variables, and each variable is defined by a set of attributes. A variable’s attributes—such as units, name and type—must not be confused with the data value (or values) that may be represented by that variable. A variable called time may contain an integer number of minutes, but it does not contain a particular number of minutes until a context, such as a specific event recorded in a data set, is provided. Each variable may further be the object of an operator that defines a subset of the available data set.
Variables in the DAP have two forms. They are either base types or type constructors. Base type variables are similar to predefined variables in procedural programming languages like C or Fortran (such as int or integer*4). While these have an internal structure, it is not possible to access parts of that structure using the DAP. Base type variables in the DAP have two predefined attributes (or characteristics): name and type. They are defined as follows:
Name
A unique identifier that can be used to reference the part of the dataset associated with this variable.
Type
The data type contained by the variable. Data types include the following:
- Byte is a single byte of data. This is the same as unsigned char in ANSI C.
- Int16 is a 16 bit two’s complement integer. This is synonymous with long in ANSI C when that type is implemented as 16 bits.
- UInt16 is a 16 bit unsigned integer.
- Int32 is a 32 bit two’s complement integer. This is synonymous with long in ANSI C when that type is implemented as 32 bits.
- UInt32 is a 32 bit unsigned integer.
- Float32 is the IEEE 32 bit floating point data type.
- Float64 is the IEEE 64 bit floating point data type.
- String is a sequence of bytes terminated by a null character.
- Url is a string containing an OPeNDAP URL.
The declaration in a DDS of a variable of any of the base types is simply the type of the variable followed by its name and a semicolon. For example, to declare a month variable to be a 32-bit integer, you would type:
Int32 month;
Constructor Types
Constructor types, such as arrays and structures, describe the grouping of one or more variables within a dataset. These classes are used to describe different types of relations between the variables that comprise the dataset. For example, an array might indicate that the variables grouped are all measurements of the same quantity with some spatial relation to one another, whereas a structure might indicate a grouping of measurements of disparate quantities that happened at the same place and time.
There are six classes of type constructor variables defined by OPeNDAP: arrays, structures, sequences, functions, and grids. These are explained below.
Array
An array is a one dimensional indexed data structure as defined by ANSI C. Multidimensional arrays are defined as arrays of arrays. An array may be subsampled using subscripts or ranges of subscripts enclosed in brackets ([]). For example, temp[3][4] would indicate the value in the fourth row and fifth column of the temp array. (As in C, OPeNDAP array indices start at zero.)
A chunk of an array may be specified with subscript ranges; the array temp[2:10][3:4] indicates an array of nine rows and two columns whose values have been lifted intact from the larger temp array.
NOTE: A hyperslab may be selected from an array with a stride value. The array represented by temp[2:2:10][3:4] would have only five rows; the middle value in the first subscript range indicates that the output array values are to be selected from alternate input array rows. The array temp[2:3:10][3:4] would select from every third row, and so on.
A DDS declaration of a 5x6 array of floating point numbers would look like this:
Float64 data[5][6];
In addition to its magnitude, every dimension of an array may also have a name. The previous declaration could be written as:
Float64 data[height = 5][width = 6];
Structure
A Structure is a class that may contain several variables of different classes. However, though it implies that its member variables are related somehow, it conveys no relational information about them. The structure type can also be used to group a set of unrelated variables together into a single dataset. The "dataset" class name is a synonym for structure.
A DDS Structure declaration containing some data and the month in which the data was taken might look like this:
Structure {
Int32 month;
Float64 data[5][6];
} measurement;
Use the "." operator to refer to members of a Structure. For example, measurement.month would identify the integer member of the Structure defined in the above declaration.
Sequence
A Sequence is an ordered set of variables, each of which may have several values. The variables may be of different classes. Each element of a Sequence consists of a value for each member variable, so a Sequence is sort of like an ordered set of Structures.
Thus a Sequence can be represented as:
| S00 | S01 | ... | S0n |
| S10 | S11 | ... | S1n |
| S20 | S21 | ... | S2n |
| . | ... | ... | . |
| . | ... | ... | . |
| . | ... | ... | . |
| Si0 | Si1 | ... | Sin |
Every instance of Sequence S has the same number, order, and class of its member variables. A Sequence implies that each of the variables is related to each other in some logical way. For example, a Sequence containing position and temperature measurements might imply that each temperature measurement was taken at the corresponding position. A Sequence is different from a Structure because its constituent variables have several instances while a Structure’s variables have only one instance (or value).
A Sequence declaration is similar to a Structure’s declaration. For example, the following would define a Sequence that would contain many members like the Structure defined above:
Sequence {
Int32 month;
Float64 data[5][6];
} measurement;
Note that, unlike an Array, a Sequence has no index. This means that a Sequence’s values are not simultaneously accessible. Instead, a Sequence has an implied state, corresponding to a single element in the Sequence.
As with a Structure, the variable measurement.month has a single value. The distinction is that this variable’s value changes depending on the state of the Sequence. You can think of a Sequence as composed of the data you get from successive reads of data from a file. The data values available at any point are the last values read from the file, and you will not have immediate access to any of the other values in that file.
Grid
A Grid is an association of an N dimensional array with N named vectors (one-dimensional arrays), each of which has the same number of elements as the corresponding dimension of the array. Each data value in the Grid is associated with the data values in the vectors associated with its dimensions.
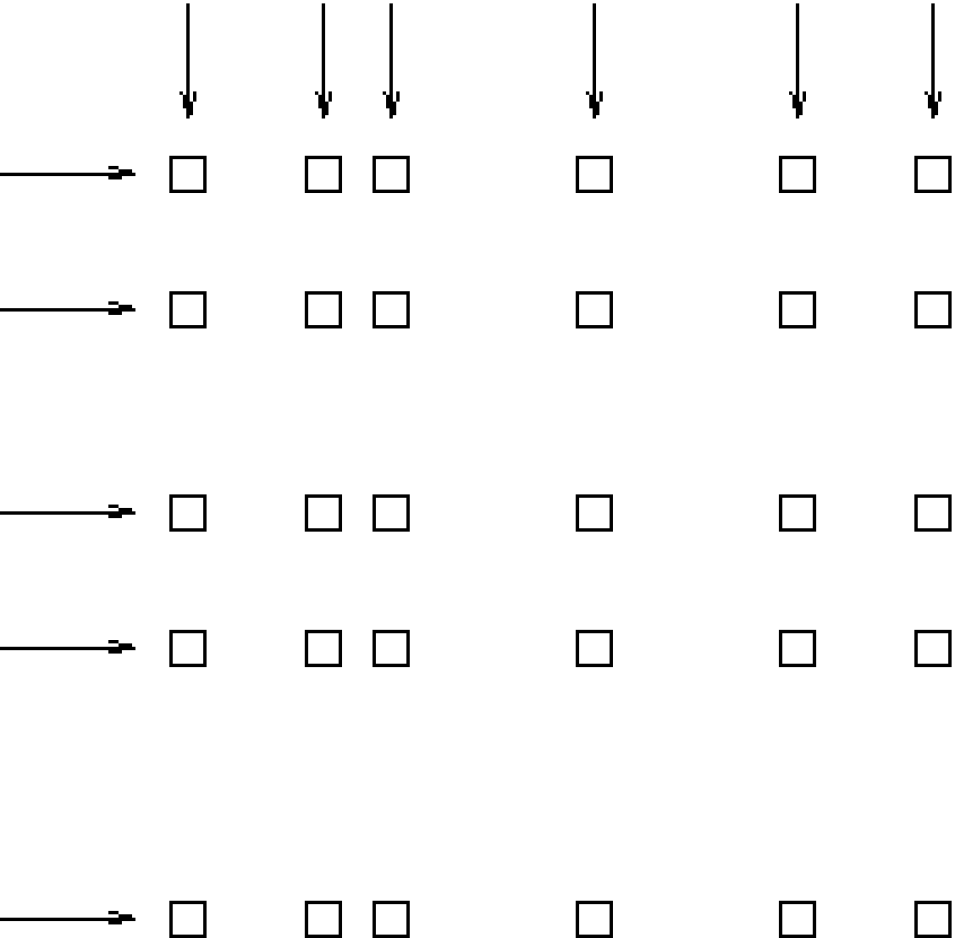
For example, consider an array of temperature values that has six columns and five rows. Suppose that this array represents measurements of temperature at five different depths in six different locations. The problem is the indication of the precise location of each temperature measurement, relative to one another.
If the six locations are evenly spaced, and the five depths are also evenly spaced, then the data set can be completely described using the array and two scalar values indicating the distance between adjacent vertices of the array. However, if the spacing of the measurements is not regular, as in the figure below, then an array will be inadequate. To adequately describe the positions of each of the points in the grid, the precise location of each column and row must be described.