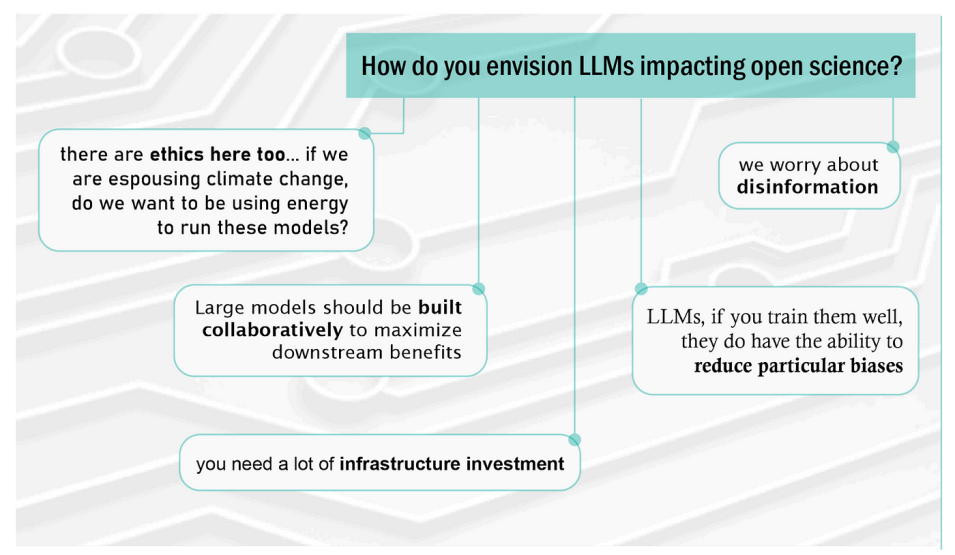
In a recent IMPACT blog article, Kaylin Bugbee, lead of the Science Discovery Engine project, and Rahul Ramachandran, IMPACT project manager, explored the ethical implications of using generative large language models (LLMs) in the context of scientific documentation. These machine learning models are examples of foundation models which rely on neural network learning algorithms to analyze massive quantities of text data. After substantial training, LLMs are capable of diverse tasks, including language prediction and novel text generation.
In their article, Kaylin and Rahul discussed how the proliferation of LLMs has recently given rise to applications such as OpenAI’s GPT-3 and Google’s BERT (Bidirectional Encoder Representations from Transformers), and they considered how these tools may influence how scientific output is accessed and legitimized. Given that IMPACT is beginning a partnership with IBM to build AI foundation models for several Earth data analysis projects, the fundamental question of how LLM development and use intersects with open science principles is worthy of thorough examination. IMPACT recently capitalized on the opportunity to jointly delve into this topic with a group visiting from IBM research through a moderated, informal lunch-time discussion regarding open science and LLMs.
Kaylin opened the exchange by sharing how both NASA and IMPACT view the definition and core tenets of open science. She explained:
"Open science is a collaborative culture enabled by technology that empowers the open sharing of data, information, and knowledge within the scientific community and the wider public to accelerate scientific research and understanding."