(Editor’s note: NASA's Interagency Implementation and Advanced Concepts Team (IMPACT) is a component of NASA’s Earth Science Data Systems (ESDS) Program, and works to further ESDS’s goal of overseeing the lifecycle of Earth science data to maximize the scientific return of NASA’s missions and experiments for research and applied scientists, decision makers, and society.)
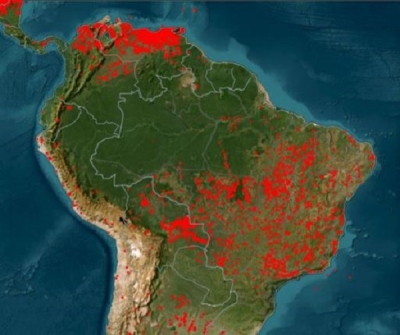
There is a scientific need for more frequent global surface reflectance observations for land monitoring applications. To address this need, observations from instruments on multiple platforms can be used to improve temporal coverage. To combine data from similar instruments and platforms, the data must be harmonized, or made more consistent. To provide the frequent observations needed, the Harmonized Landsat 8 Sentinel-2 (HLS) data products were developed by a team at NASA’s Goddard Space Flight Center in Greenbelt, MD. The HLS algorithm had been implemented for more than 120 test sites worldwide covering approximately 28% of the globe.

As described in an earlier blog post, the IMPACT team was tasked with expanding the implementation of the HLS algorithm from the initial 120 sites to a global scale, generating data products in near real-time along with a full archive of the HLS data products. To provide global HLS data, the team knew they would have to go to the cloud. Reliable production of HLS data products at the global scale requires a cloud-based processing approach. Such an approach allows for the scaling of compute resources to accommodate the variable needs of HLS data production. To accomplish their mandate the team concluded that migrating to Amazon Web Services (AWS) was necessary to streamline development, facilitate dynamic scaling for archival processing, and optimize data transfer to NASA’s Land Processes Distributed Active Archive Center (LP DAAC) cloud distribution system.
At its core the HLS project constitutes a large data bakery. It takes ingredients (Sentinel-2, Landsat 8, Terra, and Aqua data) and processes those separate ingredients to produce a uniform, coherent view of the planet’s surface. These input ingredients are produced by partners at the United States Geological Survey (Landsat 8) and the European Space Agency (Sentinel-2), so the HLS pipeline uses an event driven architecture to continuously transform the data inputs as they become available in near real-time. The HLS project utilizes AWS for two main purposes: orchestration and compute. Orchestration involves listening for new data availability, downloading the input data from external providers and tracking the various stages of input data processing. Compute is where the real work occurs, and scientific algorithms are used to transform raw input data into final products for publication.

Historically, the production of planetary-scale Earth observation products has been managed by high performance compute clusters and on-premise data production systems. Cloud-based production systems provide two advantages to this approach. While on-premise systems are capable of processing data at very large scales, a network bottleneck exists when moving data between on-premise systems and end users. This bottleneck has become increasingly problematic as Earth observation data volumes have exploded. Producing data using cloud-based systems allows direct delivery to massively scalable cloud storage systems where scientists can perform large scale analysis with data-proximate computing resources while avoiding any network-based limitations.
Cloud-based production systems also provide flexibility and can adjust to variable processing resource demands. Generating products on a regular schedule requires a consistent amount of computing resources. However, products such as HLS can require a massive scaling of resources to support archival processing for historical data or re-processing due to algorithm updates. Cloud-based production systems can scale quickly and efficiently so that these large processing efforts can be accomplished on tighter schedules and products can be delivered more rapidly to the scientific community.
HLS team member Sean Harkins articulates the promise that cloud platforms such as AWS offer toward realizing the research potential of the increasing volume of Earth science data:
Early in my career, I recognized the incredible value of Earth observation data to provide insights about planetary systems. I began as a data consumer, and then as my analysis requirements grew I became increasingly interested in how new and innovative scientific products could be created. I think you would be hard pressed to find many people working in this space who envisioned the volume and sophistication of data available to us today.
All of the code and resources used to construct the AWS infrastructure for the HLS project will be made available in open source repositories. These resources may be of interest to any organization undertaking large scale data processing with an event-driven model. An understanding of how the product’s reflectance values are derived can be found in the HLS user guide. An introductory (HLS Jupyter) notebook demonstrates how to leverage new data access patterns and data-proximate computing that the Cloud Optimized GeoTIFF (COG) format will support.
More information about IMPACT can be found on NASA's Earthdata website and the IMPACT project website.
Article originally published 11 February 2021 on the IMPACT blog and reprinted with permission.
Additional Resources: